본 포스팅은 '데이터 분석' 의 기초 이론의 요약을 다룹니다.
다음 포스팅 : 데이터 분석의 기초 (2) : 지도학습/비지도학습/데이터시각화
(1) 빅데이터 분석 과제 정의
[1] 문제 정의와 분석 목표 선정
* 분석 목적 : 기존 통계 분석 방식으로 분석할 수 없는 것들을 분석.
- 의사결정 : 여러 대안 중 하나의 행동을 고르는 정신적 지각 활동. 정보와 반응 사이의 단계.
- 요약 : 현 상황을 빠르고 쉽게 파악해 대응을 생각
- 불확실성 해소 : 의사결정의 가장 큰 문제를 해소
- 예측 : 특정 패턴을 파악
- 인과관계 파악 : 데이터 간 연관관계로 세부적 판단을 내림
--> 과거의 데이터를 토대로 미래를 분석한다.
*가트너 그룹 빅데이터 분석의 목적 (The Big Data Value Model(2015)
1. 고객 인사이트
2. 제품 및 절차 효율성
3. 디지털 제품 및 서비스
4. 운영의 탁월성
5. 디지털 마케팅
6. 위기 관리 시스템
*분석 기획 단계
- 분석 기획 : 목표달성 최적화를 위해 의사결정, 실행 과정에 필요한 정보와 인사이트를 과학적 분석으로 제공
1. 분석 : 어떤 문제를 해결할 것인가? 추진 가능성/추진 시급성/구현 가능성
2. 계획 : 필요데이터 정리. 데이터 목록/현황조사/데이터 공유 가능성/데이터 현황/확보방안/수집방안
* 분석 방안 설정
1. 보유 데이터와 분석 방법론을 활용해 분석 목적을 해결하기 위한 분석 방안 제시
2. 분석 방안은 기술적 해결책과 무관하게 정책 결정자와 최종 사용자 위주로 수립
3. 분석 방안이 논리적으로 이해 가능하고 구체적인지 확인
4. 분석 결과에 대한 성과 목표와 활용 방안 도출
*빅데이터 분석 프로세스
수집 - 전처리 - 후처리 - 분석 - 시각화
요건 정의 - 모델링(알고리즘) - 검증 및 테스트 - 적용
*데이터 수집
- 수집 방법 :
1. Download
2. RSS : 웹 기반 최신 데이터 공유를 위한 XML 기반 콘텐츠 공유/배급 프로토콜
3. open API : 웹 운영 주체가 공개하는 API
4. FTP : TCP/IP 프로토콜을 활용하는 인터넷 서버에서 파일 송수신
5. Crawling : Log 데이터 수집, RDB 관계형 DB에서 NoSQL/하둡 등에 저장 처리
6. Streaming : 음성/오디오/비지오 실시간 수집
(2) 데이터 수집
* 데이터 유형
By. 형태 : 정형/비정형/반정형
By. 성질 : 양적자료(수치형자료)-연속형/이산형, 질적자료(범주형자료)-명목형,순서형
| 유형 | 종류 | 수집기술 |
| 정형 데이터 | RDB, SPREAD SHEET | ETL, FTP, Open API |
| 반정형 데이터 | HTML, XML, JSON, 웹문서, 웹로그, 센서 데이터 | Crawling, RSS, Open API, FTP |
| 비정형 데이터 | 소셜 데이터, 문서, 이미지, 오디오, 비디오, IoT | Crawling, RSS, Open API, Streaming, FTP |
* 대표적인 정형 데이터
csv. RDB. MySQL.
* 대표적인 비정형 데이터
NoSQL
* 텍스트 마이닝
- 텍스트 파일의 종류 : 텍스트 파일, 바이너리 파일 (텍스트가 아닌 데이터 포함), 플레인 텍스트 파일 (몇 가지 조건_Sequence, EOF_에 부합하는 파일), 비정형 파일 (소설, 이메일, SNS 등 라인 구분 외 구조적 속성이 보이지 않는 파일), 반정형 파일 (html, xml, yaml, json 등 구조적 형태 내 자유롭게 쓰인 파일), 정형 파일 (표 형식의 텍스트 파일. 텍스트 마이닝 시에는 , 구분을 위해 tab 을 구분자로 사용)
- 텍스트 데이터 분석 : XML, API, Crawling
- Crawling 의 종류
1. 동적 크롤링 : 메모리에 로딩하여 크롤링.
파이썬 : Selenium 모듈 이용. 웹앱을 테스트.
Webdriver 라는 API 를 통해 브라우저를 제어 (직접 동작), JavaScript 를 이용해 비동기적으로 뒤늦게 불러와지는 콘텐츠를 가져올 수 있다. 사람이 실행하듯 검색하거나 링크를 누르거나 등의 행위 구현이 가능하다.
2. 정적 크롤링 : 메모리에 로딩하지 않고 크롤링. url 에 존재하는 것만 가져올 수 있다.
- API (Application Programming Interface) : 응용 프로그램에서 사용할 수 있도록 운영 체제나 프로그래밍 언어가 제공하는 기능을 제어하도록 만든 인터페이스.
(3) 데이터 전처리
[1] 데이터 전처리
1. 변환 : 평활화/집계/일반화/정규화/속성 생성
2. 여과 (filtering)
3. 정제 (cleansing) : 결측치 처리(삭제,통계값 대체,예측값_회귀분석_삽입)/이상치 처리(삭제,통계값 대체,변수화,리샘플링)/잡음 처리(구간화,회귀값 적용, 군집화)
4. 데이터 통합 : 상호연관적 데이터를 하나로 결합, 표현단위 일치 및 통합 대상 동일여부 확인 필요
5. 데이터 축소 : 분석에 불필요한 데이터 축소, 고유 특성 손상 방지, 효율성 증대 (데이터 압축/DWT/차원 축소/차원 축)
6. 데이터 세분화 : 특정 요소를 기반으로 데이터 그룹화, 목표 타겟에 집중해 데이터 분석을 용이하게 함, 비용 감소
[2] 탐색적 데이터 분석 (EDA: Explaratory Data Analysis)
1. 개념적 데이터 탐색 : 변동성 유형은? 공변동은?
알아야 할 keyword : 변수/값/관측점/표로 표현된 데이터(Tabular Data)
2. 탐색적 데이터 기법
- 다중회귀분석
3. 변수 선택 기법
- 전진 선택법 : 변수를 추가하며 모형을 선택
- 후진 제거법 : 변수를 제거하며 모형을 선택
- 단계적 선택법 : 모든 부분 집합을 고려
- 기법 적용 절차 : 데이터 핸들링 -> 변수 간 관계 파악 -> 전체 모형 결정 -> 변수 선택 -> 최적모형 결정
4. 표본조사 : 모집단/표본/표본 추출/표본 조사
5. 상관성 분석 (Correlation Analysis) : 상관관계 분석
- 기본 가정 : 선형성 (두 변인이 직선적인가? 산점도로 확인), 동변량성(이분산성의 반댓말. X에 관계없이 Y의 흩어진 정도가 같은가?), 정규분포성(측정치 분포가 모집단에서 모두 정규 분포), 무선독립표본(모집단에서 뽑을 때 표본대상이 확률적으로 선정됨)
- 상관 분석 방법 : 단순 상관 분석 (2개의 변수), 다중 상관 분석 (3개 이상의 변수), 편상 관계 분석 (다중 상관 분석에서 다른 변수들과의 관계를 고정하고, 두 변수만의 관계에 대한 강도를 나타냄)
- 피어슨 상관 계수
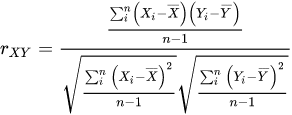

- 스피어만 상관 계수 : 서열척도에서 값 대신 순위를 이용
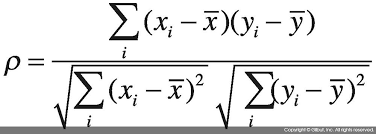
1은 한쪽의 순위가 증가함에 따라 다른 쪽의 순위도 증가함을 뜻하고, -1은 한쪽의 순위가 증가할 때 다른 쪽의 순위는 감소함을 뜻한다. 0은 한쪽의 순위 증가가 다른 쪽의 순위와 연관이 없음을 뜻한다.
[3] 시각화를 통한 탐색적 자료 분석
1. 빈도 분석 : Bar chart / Pie Chart
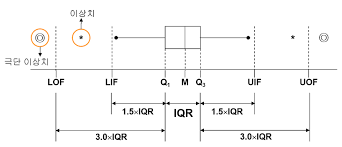
2. 측정형 변수 : 기초 통계량의 시각화. Box Plot, 산점도, 막대 그래프, 히스토그램, 히트맵
- EDA 를 위한 파이썬 라이브러리 : numpy, pandas, matploylib, sebom
'PROGRAMMING > Data Analysis' 카테고리의 다른 글
| [데이터 분석] (1) 데이터 분석이란? (0) | 2021.11.19 |
|---|---|
| [데이터 분석] (응용)미디어 데이터분석 - 기초 이론 (0) | 2021.10.16 |
| [데이터 분석] (sumUP2) : 지도학습/비지도학습/데이터시각화 (0) | 2021.10.16 |
| [데이터 분석] (3-1) 데이터 수집 예제 : 편의점 통계 데이터 (0) | 2021.10.15 |
| [데이터 분석] (3-2) 데이터 수집 예제 : 뉴스 웹크롤링 (0) | 2021.10.15 |




댓글