
Pandas 를 이용한 데이터 수집
안녕하세요!
지난 포스팅에서, 데이터 수집이 무엇인지, 어떤 절차를 거치는지 알아 보았습니다.
이번 글에서는 정형 데이터를 Pandas 를 이용해 분석하는 예제를 다룰게요!
말머리 [데이터 분석] 으로 검색해주세요!
<요약글>
[데이터 분석] (sumUP1) : 빅데이터 분석/데이터 수집/데이터 전처리
[데이터 분석] (sumUP2) : 지도학습/비지도학습/데이터시각화
[데이터 분석] (응용)미디어 데이터분석 - 기초 이론
기본적으로 "." 으로 구분되는 CSV 파일이 데이터 분석에 이용될 예정입니다.
* 분석 절차
1. 로컬 컴퓨터의 csv 파일 업로드하기
2. data 확인하기
3. data 기본 특성 및 통계량 확인하기
4. 조건에 맞는 data 찾기
5. 조건에 맞는지 확인하는 열 추가하기 (True, False)
6. 조건에 맞는 데이터만 새로 csv 로 저장하기
7. 데이터 기본 시각화 : 히스토그램, 박스 플롯 (box plot)
https://github.com/NRKode/Data-Analysis/tree/main/Basic_preProcessing
GitHub - NRKode/Data-Analysis: Data Analysis and Visualization
Data Analysis and Visualization. Contribute to NRKode/Data-Analysis development by creating an account on GitHub.
github.com
1. 로컬 컴퓨터의 csv 파일 업로드하기
from google.colab import files
uploaded = files.upload()본 업로드 방식은 로컬 컴퓨터 파일을 한 개씩 업로드하는 방법입니다.
저는 GitHub 에 업로드한 csv 파일을 사용했습니다.
- convenient_store_ansi.csv(application/vnd.ms-excel) - 10454 bytes, last modified: 2020. 11. 13. - 100% doneSaving convenient_store_ansi.csv to convenient_store_ansi (2).csv
- 이와 같이 확인 문구가 뜨면 성공입니다.
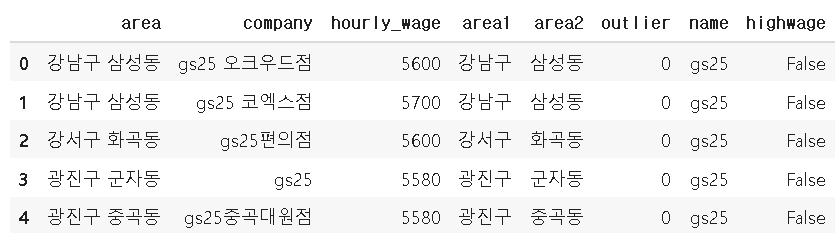
data = pd.read_csv('convenient_store_ansi.csv',encoding='cp949')
data.head(8) #8줄 확인하기이 때, 로컬 컴퓨터에서 불러왔으므로 encoding 을 하지 않으면 error 가 납니다.
areacompanyhourly_wagearea1area2outliername01234567
| 강남구 삼성동 | gs25 오크우드점 | 5600 | 강남구 | 삼성동 | 0 | gs25 |
| 강남구 삼성동 | gs25 코엑스점 | 5700 | 강남구 | 삼성동 | 0 | gs25 |
| 강서구 화곡동 | gs25편의점 | 5600 | 강서구 | 화곡동 | 0 | gs25 |
| 광진구 군자동 | gs25 | 5580 | 광진구 | 군자동 | 0 | gs25 |
| 광진구 중곡동 | gs25중곡대원점 | 5580 | 광진구 | 중곡동 | 0 | gs25 |
| 구로구 구로동 | gs25구로동양점 | 6000 | 구로구 | 구로동 | 0 | gs25 |
| 구로구 구로동 | gs25구로동양점 | 5580 | 구로구 | 구로동 | 0 | gs25 |
| 동대문구 장안동 | gs25장안중앙점 | 5600 | 동대문구 | 장안동 | 0 | gs25 |
8개만 데이터를 확인하기로 했으므로, 이와 같은 결과가 나옵니다.
2. data 확인하기
data.info() #dataframe 형태 저장 및 레코드수 (177), 컬럼 수(7), 용량 확인기본적인 데이터를 확인할 수 있습니다.
<class 'pandas.core.frame.DataFrame'> RangeIndex: 177 entries, 0 to 176 Data columns (total 7 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 area 177 non-null object 1 company 177 non-null object 2 hourly_wage 177 non-null int64 3 area1 177 non-null object 4 area2 177 non-null object 5 outlier 177 non-null int64 6 name 177 non-null object dtypes: int64(2), object(5) memory usage: 9.8+ KB
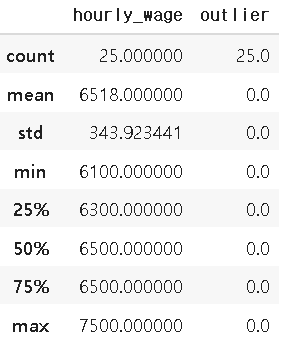
3. data 기본 특성 및 통계량 확인하기
data.describe() #빈도,평균,편차,최소,최대,25/50/75% 확인_숫자에 대해서만 하는 것 같다.
4. 조건에 맞는 data 찾기
data.area.describe()먼저, area 컬럼의 내용을 확인합니다.
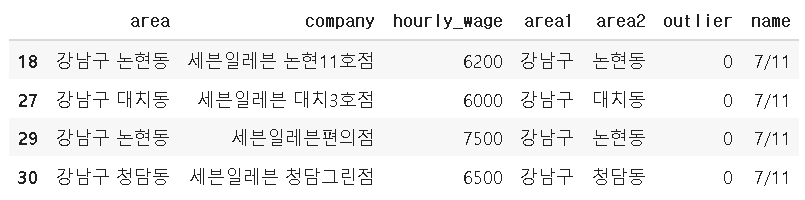
highwage=data[(data.hourly_wage>=6000)&(data.area1=='강남구')&(data.company.str.contains('세븐일레븐'))]
highwage.head()임금 6000 이상, 강남구, 세븐일레븐의 조건을 넣고 데이터를 확인합니다.
5. 조건에 맞는지 확인하는 열 추가하기 (True, False)
data['highwage']=data.hourly_wage>6000 #조건문: True,False 로 적용된다. 새로운 컬럼이 생성된다.
data.head()임금이 6000 이상인 행에 대해 True, False 로 새로운 열을 만들어 줍니다.
data[data.highwage==True].describe() #True 에 대한 data 특성을 확인한다.본 데이터에 대해, highwage 가 True 인 데이터의 통계량을 확인합니다.
6. 조건에 맞는 데이터만 새로 csv 로 저장하기
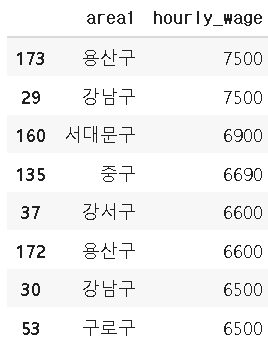
data_re=data[data.highwage==True][['area1','hourly_wage']] #True 에 대해 area, hourly_wage 에 대해 정리하고
data_re=data_re.sort_values(by='hourly_wage',ascending=0) #hourly_wage 로 오름차순 정렬한다.
data_re.head(8) #상위 8개만 보인다.True을 갖는 데이터에 대해 area1과 임금만 남기고, 임금에 대해 오름차순 정렬을 합니다.
상위 8개만 확인해 봅니다.
data_re.to_csv('data.csv',index='False')csv로 저장합니다.
index 는 데이터에 대해 색인 처리를 할 지 옵션 설정을 하는 것으로, True 설정을 하면 열 하나가 추가되고 넘버링됩니다.
여기서는 굳이 넘버링을 할 필요가 없어, False 로 지정합니다.
7. 데이터 기본 시각화 : 히스토그램, 박스 플롯 (box plot)
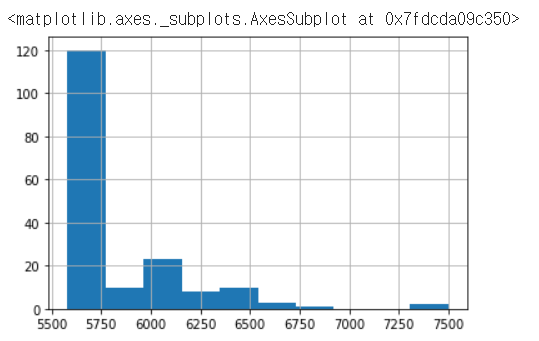
data.hourly_wage.hist(bins=10) #10구간으로 히스토그램 시각화hist(bins=구간) 함수를 사용합니다.
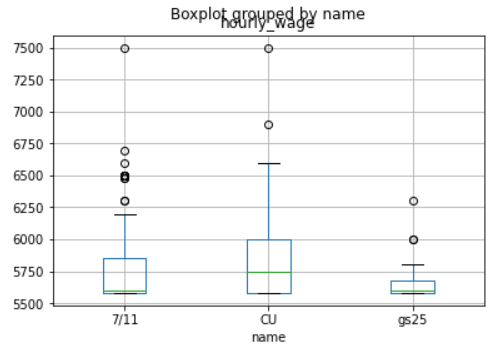
data.boxplot(column='hourly_wage',by='name')boxplot(표현할 행, 이름) 함수를 이용합니다.
'PROGRAMMING > Data Analysis' 카테고리의 다른 글
| [데이터 분석] (1) 데이터 분석이란? (0) | 2021.11.19 |
|---|---|
| [데이터 분석] (응용)미디어 데이터분석 - 기초 이론 (0) | 2021.10.16 |
| [데이터 분석] (sumUP2) : 지도학습/비지도학습/데이터시각화 (0) | 2021.10.16 |
| [데이터 분석] (sumUP1) : 빅데이터 분석/데이터 수집/데이터 전처리 (2) | 2021.10.16 |
| [데이터 분석] (3-2) 데이터 수집 예제 : 뉴스 웹크롤링 (0) | 2021.10.15 |




댓글