
[ELECTRONIC ELECTRICAL ENG/컴퓨터 일반] - [컴퓨터 구조] 3. CPU 의 구조와 기능
[컴퓨터 구조] 3. CPU 의 구조와 기능
[ELECTRONIC ELECTRICAL ENG/컴퓨터 일반] - [컴퓨터 구조] 2. 컴퓨터 구조의 발전 3.1 CPU의 기본 구조 (1) 산술논리연산장치(Arithmetic and Logical Unit: ALU) - 각종 산술 연산들과 논리 연산들을 수행..
heynary.tistory.com
4.1 명령어 파이프라이닝 (instruction pipeline)
(1) 명령어 파이프라이닝 : CPU 의 프로그램 처리 속도를 높이기 위하여 CPU 내부 하드웨어를 여러 단계로 나누어 동시에 처리하는 기술
- 2 단계 명령어 파이프라인 (two stage instruction pipeline) : 명령어를 실행하는 하드웨어를 인출 단계 (fetch stage) 와 실행 단계 (execute stage) 라는 두 개의 독립적인 파이프라인 모듈로 분리
- 장점) 명령어 처리 속도가 두배 향상 (일반적으로 단계 수만큼의 속도 향상)
- 단점) 두 단계의 처리 시간이 동일하지 않으면 두 배의 속도 향상을 얻지 못함 (파이프라인 효율 저하)
- 해결법)
- 파이프라인 단계의 수를 증가시켜 각 단계의 처리 시간을 같게 함
- 파이프라인 단계의 수를 늘리면 전체적으로 속도 향상

2. 4 단계 명령어 파이프라인 ::

- 명령어 인출 ( IF) 단계 : 다음 명령어를 기억장치로부터 인출
- 명령어 해독 (ID) 단계 : 해독기 (decoder) 를 이용하여 명령어를 해석
- 오퍼랜드 인출 (OF) 단계 : 기억장치로부터 오퍼랜드를 인출
- 실행 (EX) 단계 : 지정된 연산을 수행
3.파이프라인에 의한 전체 명령어 실행 시간
- 파이프라인 단계 수 = k
- 실행할 명령어들의 수 = N
- 각 파이프라인 단계가 한 클럭 주기씩 걸린다고 가정한다면
파이프라인에 의한 전체 명령어 실행 시간 T = k + (N-1)
즉, 첫 번째 명령어를 실행하는데 k 주기가 걸리고 나머지 (N-1) 개의 명령어들은 각각 한 주기씩만 소요 - 파이프라인 되지 않은 경우의 N 개의 명령어들을 실행 시간 T = k × N
- 파이프라인에 의한 속도 향상 (speed up)
예제. 파이프라인 단계 수 = 4, 파이프라인 클록 = 1 GHz, 각 단계에서의 소요시간 = 1ns 일 때 10개의 명령어를 실행하는 경우의 속도향상?
풀이.
첫 번째 명령어 실행에 걸리는 시간 = 4 ns
다음부터는 매 1 ns 마다 한 개씩의 명령어 실행 완료
-> 10개의 명령어 실행 시간 = 4 + (10 1) = 13 ns
-> 속도향상 = (10 × 4) / 13 ≒ 3.08 배
=> N이 커질수록 Sp -> k 값에 근접한다.
4. 파이프라인의 효율 저하 요인들
- 모든 명령어들이 파이프라인 단계들을 모두 거치지는 않는다.
- 어떤 명령어에서는 오퍼랜드를 인출할 필요가 없지만 파이프라인의 하드웨어를 단순화시키기 위해서는 모든 명령어가 네 단계들을 모두 통과하도록 해야 한다
- 파이프라인의 클록은 처리 시간이 가장 오래 걸리는 단계를 기준으로 결정된다.
- IF 단계와 OF 단계가 동시에 기억장치를 액세스하는 경우에 기억장치 충돌 (memory conflict) 이 일어나면 지연이 발생한다
- 조건 분기 (conditional branch) 명령어가 실행되면 , 미리 인출하여 처리하던 명령어들이 무효화된다
5. 분기발생에 의한 성능 저하의 최소화 방법
- 분기 예측 (branch prediction) : 분기가 일어날 것인 지를 예측하고 , 그에 따라 명령어를 인출하는 확률적 방법
- 분기 역사 표 (branch history table) 이용하여 최근의 분기 결과를 참조
- 분기 목적지 선인출 (prefetch branch target): 조건 분기가 인식되면 , 분기 명령어의 다음 명령어뿐만 아니라 분기의 목적지 명령어도 함께 인출하는 방법
- 루프 버퍼 (loop buffer) 사용 : 파이프라인의 명령어 인출 단계에 포함되어 있는 작은 고속 기억장치인 루프 버퍼에 가장 최근 인출된 n 개의 명령어들을 순서대로 저장해두는 방법
- 지연 분기 (delayed branch): 분기 명령어의 위치를 재배치함으로써 파이프라인의 성능을 개선하는 방법
6. 상태 레지스터 (status register)
- 조건분기 명령어가 사용할 조건 플래그 (condition flag) 들 저장
- 부호 (S) 플래그 : 직전에 수행된 산술연산 결과값의 부호 비트를 저장
- 영 (Z) 플래그 : 연산 결과값이 0 이면 , 1
- 올림수 (C) 플래그 : 덧셈이나 뺄셈에서 올림수 (carry) 나 빌림수(borrow) 가 발생한 경우에 1 로 세트
- 동등 (E) 플래그 : 두 수를 비교한 결과가 같게 나왔을 경우에 1로 세트
- 오버플로우 (V) 플래그 : 산술 연산 과정에서 오버플로우가 발생한 경우에 1 로 세트
- 인터럽트 (I) 플래그
- 인터럽트 가능 (interrupt enabled) 상태이면 0 로 세트
- 인터럽트 불가능 (interrupt disabled) 상태이면 1 로 세트
- 슈퍼바이저 (P) 플래그 :
- CPU 의 실행 모드가 슈퍼바이저 모드 (supervisor mode) 이면 1 로 세트
- 사용자 모드 (user mode) 이면 0 로 세트
(2) 슈퍼스칼라 (super scalar)
- CPU 의 처리 속도를 더욱 높이기 위하여 내부에 두 개 혹은 그 이상의 명령어 파이프라인들을 포함시킨 구조
- 매 클록 주기마다 각 명령어 파이프라인이 별도의 명령어를 인출하여 동시에 실행할 수 있기 때문에 이론적으로는 프로그램 처리 속도가 파이프라인의 수만큼 향상 가능
- 파이프라인의 수 = m --> m-way 슈퍼스칼라
1. 슈퍼스칼라에 의한 속도향상(speedup: Sp)
- 단일 파이프라인에 의한 실행 시간 (N : 실행할 명령어 수)
T(1) = k + N - 1
- mway 슈퍼스칼라에 의한 실행 시간
T(m)=k+ (N-m)/m
- 속도향상 Sp = T(1)/T(m) = m(k + N - 1)/{N+m(k-1)}
- N이 커질수록 sp --> m
2. 슈퍼스칼라의 속도 저하 (Sp < m) 요인
- 명령어들 간의 데이터 의존 관계
- 하드웨어 (ALU, 레지스터 , 등 ) 이용에 대한 경합 발생
- 동시 실행 가능한 명령어 수 < m
3. 해결책
- 명령어 실행 순서 재배치
명령어들 간의 데이터 의존성 제거 - 하드웨어 추가 중복 설치
기억장치 및 레지스터에 대한 경합 감소
(3) 듀얼 코어 및 멀티 코어
1. CPU 코어 ( core): 명령어 실행에 필요한 CPU 내부의 핵심 ( 명령어 실행 ) 하드웨어 모듈
2. 멀티 코어 프로세서 (multi core processor): 여러 개의 CPU 코어들을 하나의 칩에 포함시킨 프로세서
= 칩 레벨 다중프로세서 (chip level multiprocessor) 혹은 단일 칩 다중프로세서 (multiprocessor on a chip)
- 듀얼 코어 (dual core): 두 개의 CPU 코어 포함
- 쿼드 코어 (quad core): 네 개의 CPU 코어 포함
3. 각 CPU 코어는 별도의 H/W 모듈로 이루어지며 , 시스템 버스와 캐시만 공유
- 프로그램 실행에 있어서 각 코어는 슈퍼스칼라의 각 파이프라인보다 더 높은 독립성 가짐
- 멀티 태스킹 (multi tasking) 혹은 멀티 스레딩 (multi threading)
4.2 명령어 세트
- 어떤 CPU 를 위하여 정의되어 있는 명령어들의 집합
- 명령어 세트 설계를 위해 결정되어야 할 사항들
- 연산 종류 (operation repertoire) : CPU 가 수행할 연산들의 수와 종류 및 복잡도
- 데이터 형태 (data type) : 연산을 수행할 데이터들의 형태 , 데이터의 길이 ( 비트 수 ), 수의 표현 방식 등
- 명령어 형식 (instruction format) : 명령어의 길이 , 오퍼랜드 필드들의 수와 길이 등
- 주소지정 방식 (addressing mode) : 오퍼랜드의 주소를 지정하는 방식
(1) 연산의 종류
- 데이터 전송 : 레지스터와 레지스터 간 , 레지스터와 기억장치 간 , 혹은 기억장치와 기억장치 간에 데이터를 이동하는 동작
- 산술 연산 : 덧셈 , 뺄셈 , 곱셈 및 나눗셈과 같은 기본적인 산술 연산들
- 논리 연산 : 데이터의 각 비트들 간에 대한 AND, OR, NOT , exclusive OR 연산
- 입출력 (I/ O): CPU 와 외부 장치들 간의 데이터 이동을 위한 동작들
- 프로그램 제어 : 명령어 실행 순서를 변경하는 연산들
- 분기 (branch)
- 서브루틴 호출 (subroutine call)
- CALL X 명령어 : 현재의 PC 내용을 스택에 저장하고 서브루틴의 시작 주소로 분기하는 명령어
- 마이크로 연산
- t0 : MBR <- PC
- t1 : MAR <- SP, PC <- X
- t2 : M[MAR] <- MBR, SP <- SP - 1
- 현재의 PC 내용 (서브루틴 수행 완료 후에 복귀할 주소) 을 SP 가 지정하는 스택의 최상위에 저장
- 만약 주소지정 단위가 바이트이고 저장될 주소는 16 비트라면
SP <- SP - 2 로 변경
- 마이크로 연산
- RET 명령어 : CPU 가 원래 실행하던 프로그램으로 복귀시키는 명령어
- 마이크로 연산
- t0 : SP <- SP + 1
- t1 : MAR <- SP
- t2 : PC <- M[MAR]
- 마이크로 연산
- CALL X 명령어 : 현재의 PC 내용을 스택에 저장하고 서브루틴의 시작 주소로 분기하는 명령어
(2) 명령어 형식
- 명령어의 구성요소들
- 연산 코드 (Operation Code) : 수행될 연산을 지정 예 : LOAD, ADD 등
- 오퍼랜드 (Operand) : 연산을 수행하는 데 필요한 데이터 혹은 데이터의 주소
- 각 연산은 한 개 혹은 두 개의 입력 오퍼랜드들과 한 개의 결과 오퍼랜드를 포함
- 데이터는 CPU 레지스터 , 주기억장치 , 혹은 I/O 장치에 위치
- 다음 명령어 주소 (Next Instruction Address) : 현재의 명령어 실행이 완료된 후에 다음 명령어를 인출할 위치 지정
- 분기 혹은 호출 명령어와 같이 실행 순서를 변경하는 경우에 필요
- 명령어의 형식
- 명령어 형식(instruction format) : 명령어 내 필드들의 수와 배치 방식 및 각 필드의 비트 수
- 필드(field) : 명령어의 각 구성 요소들에 소요되는 비트들의 그룹
- 명령어의 길이 = 단어(word) 길이
- 고려할 사항들
- 연산 코드 필드 길이 : 연산의 개수를 결정
- 예 ] 4 비트 : 2^4 = 16 가지의 연산 정의 가능
- 연산 코드 필드가 늘어나면 다른 필드의 길이가 감소
- 오퍼랜드 필드의 길이 : 오퍼랜드의 범위 결정, 오퍼랜드의 종류에 따라 범위가 달라짐
- 데이터 : 표현 가능한 수의 범위 결정
- 2의 보수로 표현되는 데이터라면, 12비트일 때 : -2048 ~ 2047
- 기억장치 주소 : CPU 가 오퍼랜드 인출을 위하여 직접 주소를 지정할 수 있는 기억장치 용량 결정
- 8 비트 -> 기억장치의 주소 범위 : 0 ∼ 255 번지
- 레지스터 번호 : 데이터 저장에 사용될 수 있는 레지스터의 개수 결정
- 4 비트 : 16 개의 레지스터 사용 가능
- 데이터 : 표현 가능한 수의 범위 결정
- 연산 코드 필드 길이 : 연산의 개수를 결정
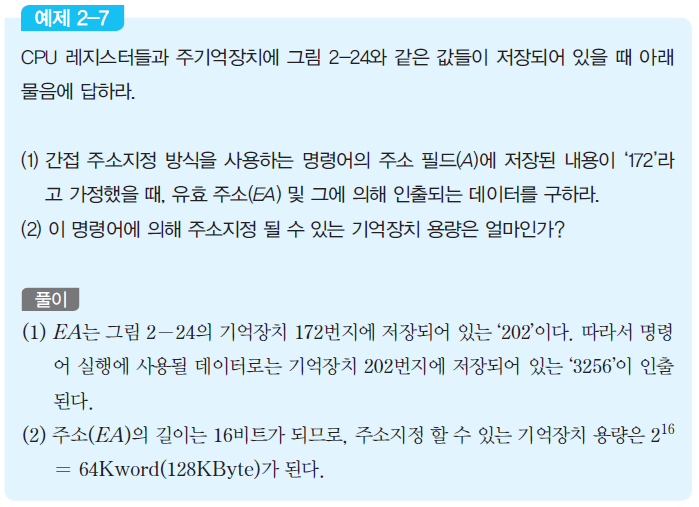
(3) 주소지정 방식
- 명령어 실행에 필요한 오퍼랜드 데이터 의 주소를 결정하는 방식
- 기억장치 주소 : 데이터가 저장된 기억장치의 위치를 지정
- 레지스터 번호 : 데이터가 저장된 레지스터를 지정
- 데이터 : 명령어의 오퍼랜드 필드에 데이터가 포함






'ELECTRONIC ELECTRICAL ENG > 컴퓨터 일반' 카테고리의 다른 글
| [컴퓨터 구조] 6. 정수와 부동소수점 연산 (0) | 2022.06.05 |
|---|---|
| [컴퓨터 구조] 5. 컴퓨터 산술과 논리 연산 (0) | 2022.06.05 |
| [컴퓨터 구조] 3. CPU 의 구조와 기능 (0) | 2022.06.05 |
| [컴퓨터 구조] 2. 컴퓨터 구조의 발전 (0) | 2022.06.05 |
| [컴퓨터 구조] 1. 컴퓨터시스템 개요 (0) | 2022.06.05 |




댓글