먼저 참고하면 좋은 글 : [PROGRAMMING/DATABASE] - (DBMS) 데이터베이스 기초 개념 총정리 1
[9] 물리적 데이터베이스 설계
(Key개념 : 물리적 데이터 모델링 과정 / 테이블 명세서 작성 (데이터 저장 구조, 제약 조건))
(1) 릴레이션 변환 복습
( ERD 예제 )
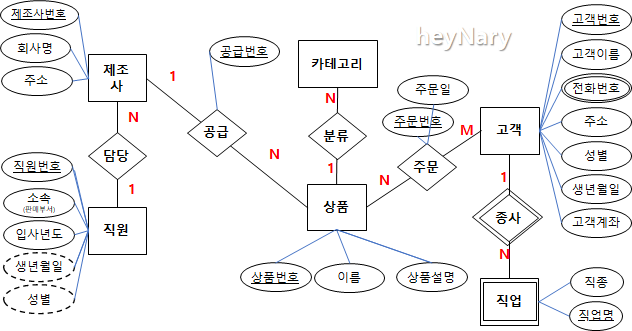
릴레이션 변환 )
- 주요 개체 : 기본키 명시, 나머지 속성 나열.
Ex. 상품
| 상품번호 | 이름 | 상품설명 |
- 약개체 : 기본키가 없으므로 필요 속성을 빌려와 기본키로 생성 (기준 개체의 기본키 + 약개체 대표 속성 합치기)
Ex. 직업
| 고객번호 | 고객 |
직종 |
- N:M : 독립된 릴레이션, 각 외래키를 넣어 릴레이션 생성
Ex. 주문
| 고객번호(FK) | 상품번호(FK) | 주문번호 | 주문일 |
- 1:N : N 쪽에 관계를 표현
EX. 제조사
| 제조사번호 | 회사명 | 주소 | 담당직원(FK) |
- 속성의 릴레이션 변환 : 다중값 속성은 한 속성에 여러 값이 들어감. 해당 개체 기본키 + 다중값 속성 합쳐 복합속성을 만들고, 복합 속성을 기본키로 하는 릴레이션 생성.
EX. 고객 전화번호
| 고객번호 | 전화번호 |
(2) 데이터 모델링 단계
- 개념적 모델링 : 서로의 상관관계 파악 / 개체, 관계, 속성 파악하고 관련성 도식화 --> ERD
- 논리적 모델링 : DBMS의 유형에 맞추어 DBMS에 저장될 데이터의 골격 (스키마) 만들기 --> 릴레이션 구조, 함수 종속성 파악
- 물리적 모델링 : 특정 BDMS에 의존하는 각종 데이터 형식, 제약조건, 뷰, 인덱스 설정 --> 테이블 정의서, 제약조건 리스트, 인덱스 명세서
* 물리적 데이터 모델 : 효율적, 구현 가능한 물리적 DB 구조 설계. DBMS 지원 방법, 응답시간, 저장공간, 트랜잭션 처리도 고려.
* 물리적 데이터베이스 스키마
1. 저장 구조 설계 : DBMS 구조, 테이블 구조, 테이블 분할, 이름 영문화 --> 표준 용어집 작성 / 사전에 정의된 명명규칙에 맞춰 변환
2. 제약조건 지정 : 데이터 형 지정, 기본키 및 기본값 정의, 체크와 규칙 정의 --> 테이블 정의서, 컬럼 정의서
3. 레코드 집중의 분석 및 설계 : 레코드 크기와 물리적 저장장치 특성에 의존 --> 주변 환경 정보 (하드웨어 자원 현황, 운영체제 현황, 파라미터 정보 파악 등), 데이터베이스 운영 정보 (관리 정책, 보안관리 정책, 백업/복구 기법 및 정책)
4. 접근 경로 설계 : 인덱스 설정, 뷰
(3) 저장구조 / 제약조건 / 접근경로
1. 저장 구조 설계
* 테이블 구조 정의 : 테이블 명, 컬럼 명, 타입, 제약조건 추가
* 데이터 타입 : 문자(열), 숫자, 날짜 타입 중 선택
[PROGRAMMING/DATABASE] - (DBMS) (공유)SQL 자료형 (데이터타입)
2. 제약 조건 지정
* 개체 무결성 제약조건
- 기본키 / 유일성 제약 (Unique) : Primary Key (Unique + Not Null) / 후보 키 (Unique, Not Null 여부 확인)
- 자연키 (Natural Key) , 인조키 (Artificial Key) : 기본키가 여러 속성이거나 크면 인조키 인위 생성
- NULL : 인덱스로 지정이 되는 컬럼에서는 Null 허용하지 않는 것이 권장. 알지 못하는 값을 표현할 때. 단순하게 값이 생략되어도 된다면 공백, 0, -1 등을 사용하는 것이 좋다.
* 참조 무결성 제약조건
- 외래키 : 1:M 에서 1, 1:1에서 Mendatory (전체가 참여하는 쪽) 에 PK을 FK로 생성, N:M은 관계 테이블 생성 후 FK 생성
* 도메인 무결성 제약조건
- 체크 제약 조건 : 올바른 값만 입력되도록 제약조건 둬야 한다. 여러 컬럼에 걸쳐 줄 수 있다. 허용 양식과 허용 값 검사.
- 기본값 : 값을 생략하면 미리 지정된 기본값이 삽입된다. 값의 생략은 허용하되 NULL 을 허용하지 않을 때 유용.
3. 접근경로 설정
* 인덱스 : 데이터의 논리적 포인터의 집합. 질의문의 빠른 수행, 컬럼값의 유일값 보장. // 그러나 인덱스 자체가 추가적인 공간을 차지하며, 인덱스 유지 관리에 추가적 시간이 소비됨.
[10] SQL / 데이터 정의어
(1) SQL (Structured Query Language) : 관계대수와 관계 해석을 기초로 한 고급 데이터 언어. 자연어와 유사한 언어이고, 비절차적 언어로 시스템 개발 및 유지보수 시간 단축 가능, 질의어와 데이터 정의/조작/제어 기능 모두 제공.
- DDL 데이터 정의어 : 구조 생성, 변경, 삭제, 데이터 구조에 대한 명령어
Ex. CREATE ALTER DROP RENAME TRUNCATE COMMENT
- DML 데이터 조작어 : 원하는 데이터 검색, 조작
Ex. SELECT INSERT UPDATE DELETE
- DCL 데이터 제어어 : DML에 의한 조작된 결과를 다루고, 접근 권한 부여, 트랜잭션에 의한 활동.
Ex. COMMINT ROLLBACK SAVEPOINT GRANT REVOKE
(2) 데이터 베이스 생성
* SQL SERVER 데이터 저장 구조 : 데이터파일 (.mdf) , 로그파일 (.ldf)
CREATE TABLE TABLE_NAME
(3) 테이블 생성
- ATTRIBUTE : 컬럼, 열 / TUPLE : 행, 레코드, 로우
- 컬럼 제약
NOT NULL
PRIMARY KEY : NOT NULL + UNIQUE, 테이블 당 하나. 자동으로 인덱스 생성됨.
UNIQUE : 중복값 허용하지 않음, NULL 가능, 테이블에 여러 개 가능.
DEFAULT VALUE : 스칼라 값 (문자, 숫자) 와 스칼라 함수 이용 가능.
FOREIGN KEY : 컬럼 모두 정의하고 나서 참조되는 테이블, 컬럼에 있는 값으로 들어가야 함.
CHECK : 도메인 무결성 조건. 삽입 데이터 검색ㅎ여 해당 영역 데이터면 진행, 아니면 삽입을 취소. TRUE, FALSE 만족하는 어떤 조건도 가능.
- 테이블 제약
PRIMARY KEY
FOREIGN KEY
CHECK
- 주요 테이블 변경
ALTER TABLE <테이블명> ADD COLUMN <컬럼명><컬럼타입>
ALTER TABLE <테이블명> DROP COLUMN <컬럼명>
ALTER TABLE <테이블명> ALTER COLUMN <이전컬럼명><컬럼명><컬럼타입>
ALTER TABLE <이전테이블명> RENAME AS <새테이블명>
[11] SQL / 관계 데이터 연산
(1) 관계 대수 - 집합 연산
* 관계 대수 (Relation Algebra) : 릴레이션 처리를 위한 연산의 집합. 피연산자와 연산 결과가 모두 릴레이션. 절차적 언어로, 관계 대수 연산자의 절차적 적용을 통해 원하는 릴레이션을 얻음. 질의(query)의 구현 및 최적화. 릴레이션 조작에 대한 이론적 기초.
* 일반 집합 연산 (Set Operation) : Union Compatible (합병가능) 릴레이션에 적용 가능 - 합집합 (Union), 교집합 (Intersection), 차집합 (Difference), 곱집합 (Cartesian Product - 서로 합병 가능하지 않아도 됨)
- 합병 가능 : R(A1, A2,..) 과 S(B1, b2,..) 가 같은 차수 n을 갖고, 1<=i<=n 인 모든 i에 대해 domain(Ai)=domain(Bi) 이면 Union Compatible
(2) 관계 대수 - 관계 연산
* 순수 관계 연산 : Select, Project, Join, Division
* Select, σ직종='IT'^고객번호='C01'(직업) : (직업) 릴레이션에서 해당 조건의 튜플 선택
* Project, π고객번호,성별(고객) : (고객) 릴레이션에서 고객번호, 성별 애트리뷰트만 갖는 릴레이션 생성. 일부 열만 선택하고 나머지 버림 (중복 제거 등)
* Join, ⟕ : 세타조인(비교연산자를 일반화해서 세타로 표현), 동등조인(=), 자연조인(동등조인에서 중복 애트리뷰트 제거), 외부조인 (outer join : 양쪽 모두 full outer/왼쪽만 결과 포함 left outer/오른쪽만 right outer)
* Division, ÷ : X⊃Y 인 릴레이션에서 R(X)와 S(Y)가 있을 때 X-Y=Z, S(Y)의 모든 튜플에 연관된 R(Z)의 튜플 선택.
(3) 관계 해석 (Relation Calculus) : 관계 조작을 위한 비절차적 방법. 무엇인지만 명시하고 어떻게 질의를 수행할 것인가는 명시하지 않음.
* 튜플 관계 해석 : QEUL (QUEry Language) - 여러 튜플 변수에 기초
Ex. {t1.A1, t2.A2, ..., tn.An|F(t1,..,tn+1,...,tn+m)}
* 도메인 관계 해석 : QBE (Query By Example) - 여러 도메인 변수에 기초
Ex. {x1,x2,..,xn|F(x1,..,xn+1,...,xn+m)}
[12] SQL - 데이터 조작어
(1) 데이터 삽입 - DEFAULT 제약 조건 가능
INSERT INTO <테이블명> [(<컬럼 리스트>)] VALUES (<값 리스트>);
- 텍스트는 작은 따옴표로 묶기
- 숫자는 그대로 사용
(2) 데이터 삭제 - 원하는 행만 삭제 가능
DELETE FROM <테이블명> [WHERE<조건>];
- WHERE 절이 없으면 모든 행을 삭제
- 특정 컬럼의 데이터 삭제는 불가능하므로 UPDATE 이용
- 외래키의 경우 삭제되지 않음, 외래키의 테이블을 삭제 시 삭제 가능.
(3) 데이터 수정 : 원하는 행의 컬럼을 주어진 값으로 바꿈
UPDATE FROM <테이블명> SET <컬럼1>=<값>, .... [WHERE <조건>]
- WHERE 절이 없으면 모든 값이 업데이트됨
- <값>에는 수식도 가능
(4) 데이터 검색 : 원하는 행 또는 열의 레코드
SELECT [DISTINCT] <컬럼리스트>
FROM <테이블리스트>
[WHERE <조건> ]
[GROUP BY <컬럼명> [HAVING <그룹조건>]]
[ORDER BY <컬럼명> [ASC / DESC]]
- SELECT * FROM : 모든 컬럼이 출력됨
* 조건 검색 : <조건식> 논리연산자 <조건식>
- 논리연산자 : NOT (논리적 부정) / AND (논리곱, 연산대상이 모두 참) / OR (하나라도 참이면 참)
- 집계 함수 : SUM(), AVG(), MAX(), MIN(), COUNT()
- 그룹별 집계 : GROUP BY (그룹 별), HAVING (그룹 별로 조건에 맞는 결과만)
[13] 데이터 종속성과 정규화
(1) 데이터베이스 구현 (논리 DB 설계)
CREATE DATABASE <TABLE명> (COLUMN명 제약조건);
USE <테이블명>;
//초기 데이터 입력-INSERT INTO 함수 사용
(2) 이상(ANOMALY)과 함수 종속
* 데이터 중복과 이상현상 : 애트리뷰트 간 여러 종속 관계가 한 릴레이션에 표헌됨
- 삽입 이상 (INSERTION ANOMALY) : 불필요하고 원치 않는 데이터도 함께 삽입해야 하고, 그렇지 않으면 삽입이 되지 않음.
- 삭제 이상 (DELETION ANOMALY) : 한 튜플을 삭제함으로써 유지해야 할 정보도 삭제됨
- 수정 이상 (MODIFICATION ANOMALY) : 중복 튜플 중 일부 튜플의 애트리뷰트 값만 갱신시켜, 정보의 모순성 (INCONSISTENCY) 생김
* 이상의 해결 : 정규화 (NOMALIZATION) - 종속관계를 분석해 여러 릴레이션으로 분해 (DECOMPOSITION)
- 스키마 변환 (SCHEMA TRANSFORMATION) - 정보의 무손실 / 데이터의 중복성 감소 / 분리의 원칙
* 함수 종속성 : 데이터 애트리뷰트와 상호관계에서 유도되는 제약조건, '애트리뷰트 집합 X의 값이 애트리뷰트 집합 Y의 값을 유일하게 (UNIQUE) 결정한다면 X는 Y를 함수적으로 결정한다 (Functionally determines)'
- 함수 종속 : 데이터의 의미 (DATA SEMANTICS) 표현, X가 Y에 종속되어 있다면 Y가 지정되면 X가 유일하게 결정됨. (R.X -> R.Y)
- 완전 함수 종속 (FULL FUNCTIONAL DEPENDENCY) : X'⊂X 이고 R.X'->R.Y를 만족하는 애트리뷰트 X가 존재 X
- 부분 함수 종속 (PARTIAL FUNCTIONAL DEPENDENCY) : X'⊂X 이고 R.X'->R.Y를 만족하는 애트리뷰트 X가 존재
(3) 릴레이션 정규화
* 정규화 원칙 : 서로 독립적인 관계는 별도 릴레이션으로 표현해야 함
* 제1정규형 (1NF : FIRST NORMAL FORM) : 릴레이션에서 애트리뷰트의 값은 도메인에 속하는 원자값이어야 함. 복합, 다중값, 중첩 릴레이션 등을 허용하지 않음.
--> 변환방법 1 : 기본키를 확장해 튜플 중복을 허용
--> 변환방법 2 : 애트리뷰트가 가질 수 있는 최대수만큼 확장
--> 변환방법 3 : 다중값을 별도 릴레이션으로 분리
* 제2정규형 (2NF) : 1NF를 만족해도 ANOMALY 존재 (삽입/삭제/수정 이상). 키에 속하지 않는 모든 애트리뷰트가 기본키에 완전 함수 종속.
--> 부분 함수종속 제거 : 프로젝션에 의한 릴레이션 분해 // 이후 자연조인을 통해 원래 릴레이션으로 복귀 가능 (무손실 분해 : NONLOSS DECOMPOSITOIN)
* 제3정규형 (3NF) : 2NF를 만족해도 ANOMALY 존재 (삽입/삭제/수정 이상). 이행적 함수 종속 존재.
--> 부분 함수종속 제거 : 프로젝션에 의한 릴레이션 분해
* BCNF (BOYCE/CODD NORMAL FORM) : 릴레이션 R의 결정자(DETERMINANT)가 후보키가 아닌 함수 종속 제거. 1)복수의 후보키가 있거나, 2) 후보키가 복합 애트리뷰트이거나, 3)R이 보이스/코드 정규형일 때. 릴레이션 R이 BCNF에 속하면 1NF~3NF 중 속한다.
* 4NF : 다치 종속 (MVD) 제거
* 5NF : 후보키를 통하지 않은 조인 종속 제거
[14] 고급 질의어 (예제 준비중)
(1) 연산자
* 비교 연산자 : =, <=, <, >, >=, != (같지 않다)
* SQL 연산자 : BETWEEN a AND b, IN(list), LIKE'비교문자열'
* 논리 연산자 : a AND b, a OR b, NOR a,
(2) 서브 쿼리 : SQL 문 안에 포함된 또 다른 SQL문, 포함된 SQL문의 결과 (R)이 SQL문의 피연산자.
(2) 조인 : 정규화 과정을 통해 분할된 테이블로부터 통합적인 정보를 얻기 위해 반드시 필요
* 카티션 프로젝트 : 테스트 용도로 대용량 테이블 생성 :
SELECT*FROM <테이블1> CROSS JOIN <테이블2>;
SELECT*FROM 테이블1, 테이블2;
* 내부 조인 : 세타 조인, 동등 조인, 자연 조인
* 외부 조인 : FULL OUTER, LEFT OUTER, RIGHT OUTER
* UNION : 둘 이상의 집합을 합성해 한 집합으로 만들어 줌.
<Copyright 2021. heynary.tistory.com. All rights reserved.>
'PROGRAMMING > DATABASE' 카테고리의 다른 글
| (DBMS) 데이터베이스 기초 개념 총정리 / 요약 1 (0) | 2021.06.12 |
|---|---|
| (DBMS) (공유)SQL 자료형 (데이터타입) (0) | 2021.06.06 |


댓글